Introduction
Embodied Decision Intelligence Lab (EDI Lab) belongs to Tsinghua University Shenzhen International Graduate School. It is supersised by Prof. Chao Yu (于超). Our lab is committed to research related to reinforcement learning infrastructure, strategic agent and embodied AI.
Chao Yu is an Associate Professor at Tsinghua University, SIGS. She is also the chairman of the Tsinghua Shenzhen International Graduate School - AgiBot Joint Research Center for Embodied Cognition and Decision Systems (JCES). As first author or corresponding author, Prof. Chao Yu has published more than 50 papers in top-tier international conferences and journals, including ICML, NeurIPS, ICLR, CVPR, ECCV, CoRL, IROS, ICRA, TMLR, and RAL, with over 6,000 citations on Google Scholar.My representative works include the multi-agent reinforcement learning algorithm MAPPO, which has received more than 3,000 Google Scholar citations, and RLinf, a large-scale reinforcement learning training framework for embodied intelligence, which has accumulated over 3,000 GitHub stars.
Our lab is currently recruiting Master’s students, Ph.D. students, joint-program Ph.D. students with Zhongguancun Academy, postdoctoral researchers, and undergraduate research assistants. We warmly welcome students who are interested in recommended admission or applying through the graduate entrance examination to SIGS programs such as Artificial Intelligence, Data Science and Information Technology, Big Data Engineering, and Electronic Engineering, as well as applicants for the above Ph.D. and postdoctoral positions, to join us.
Highlights
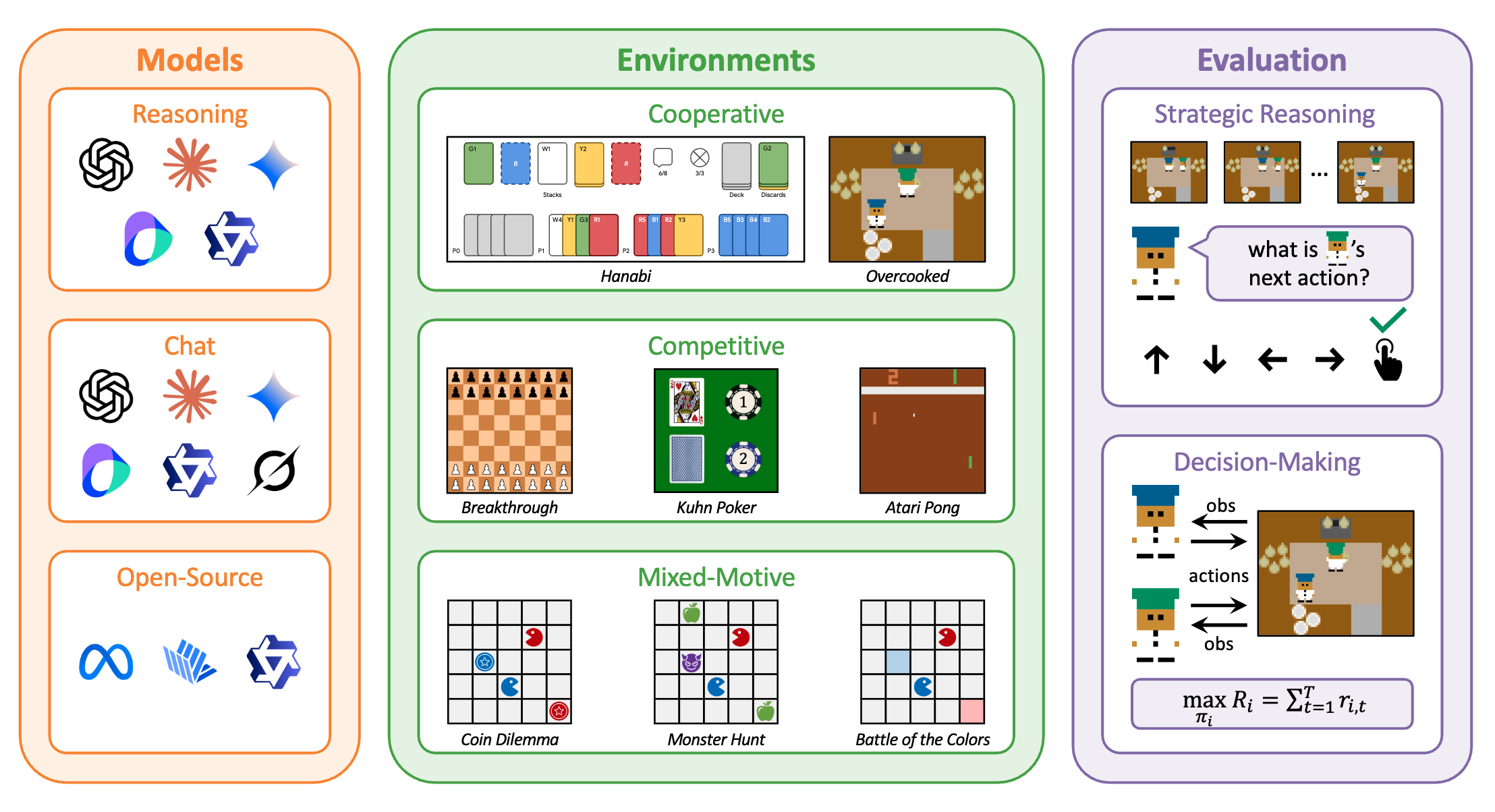
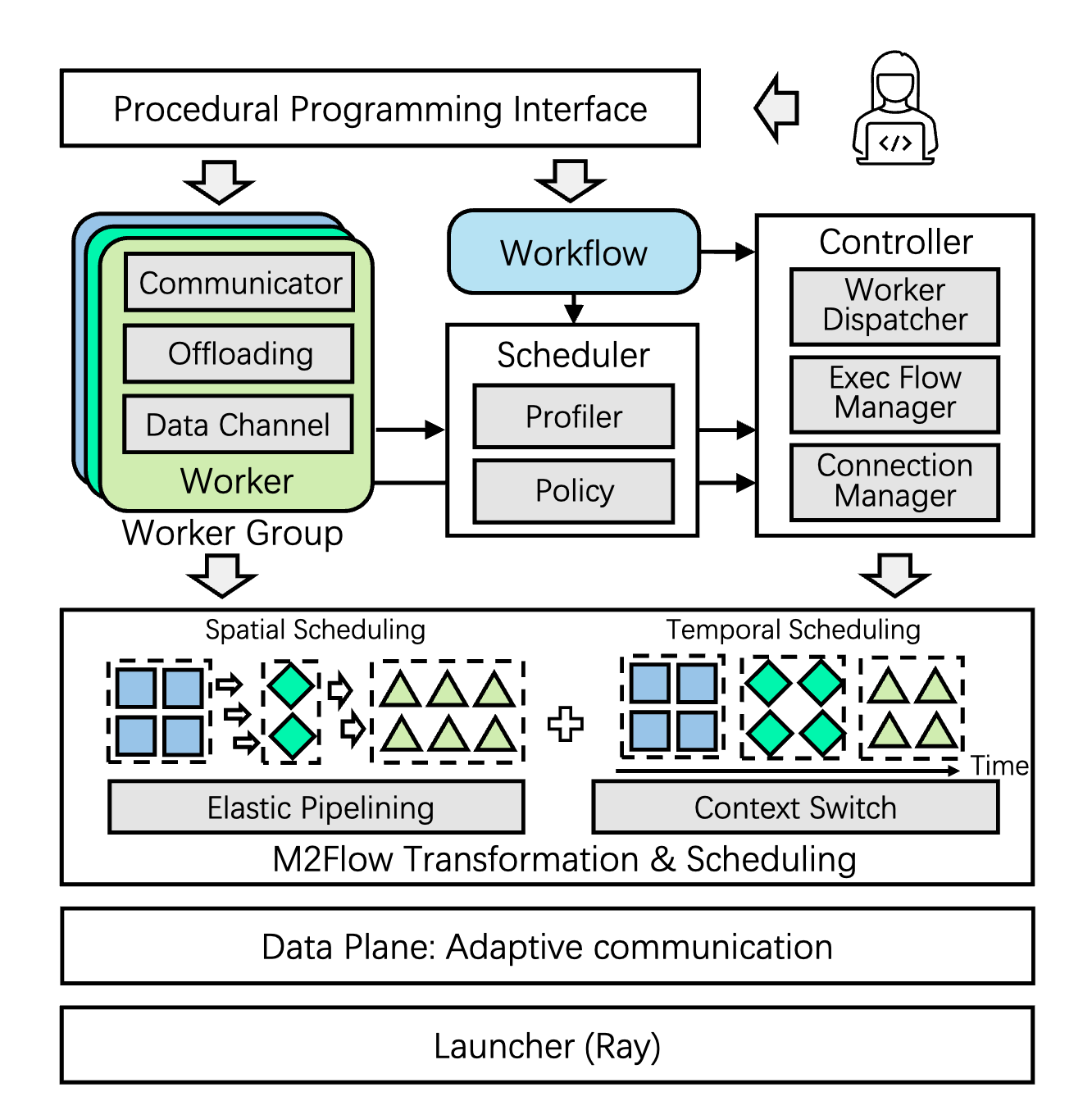
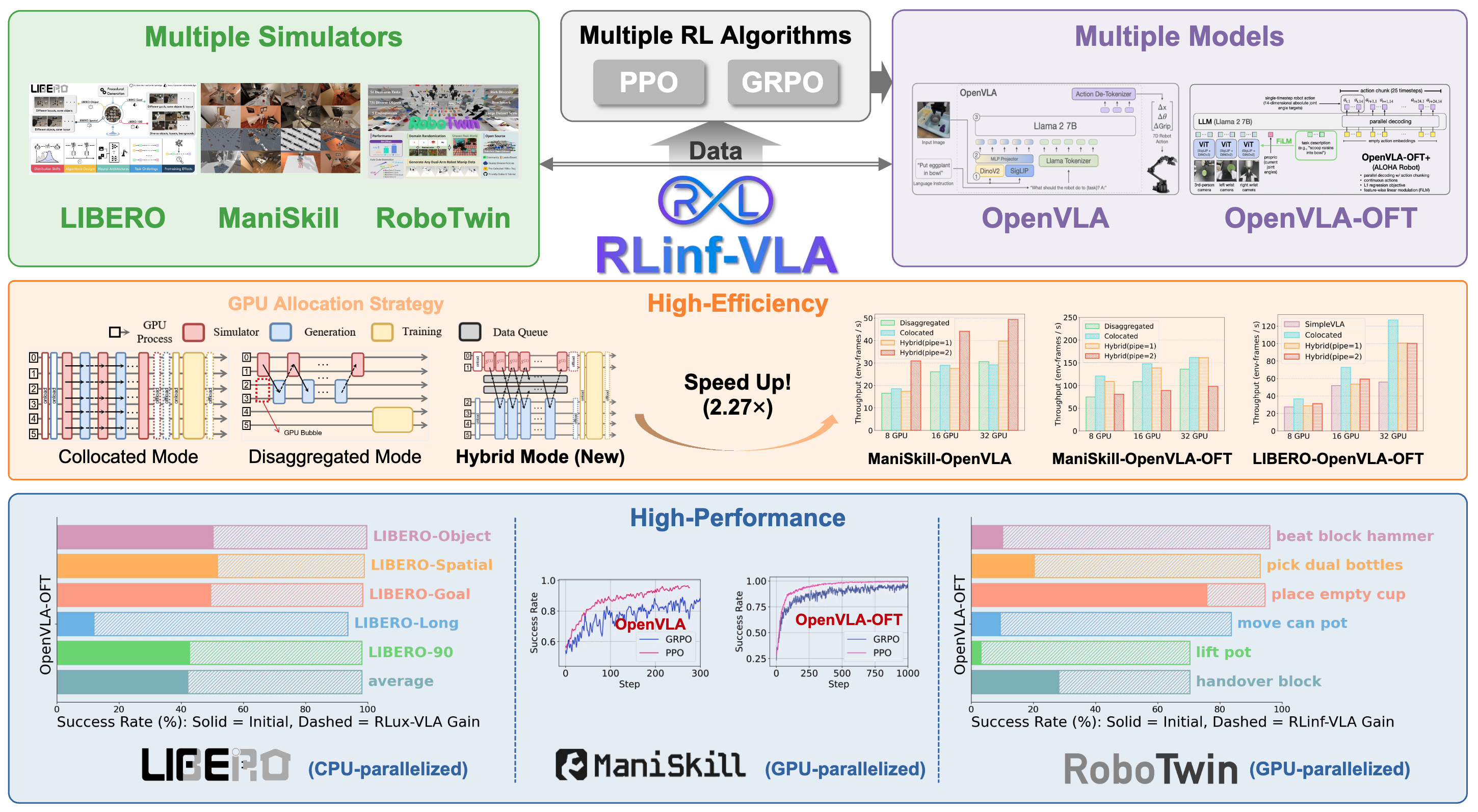
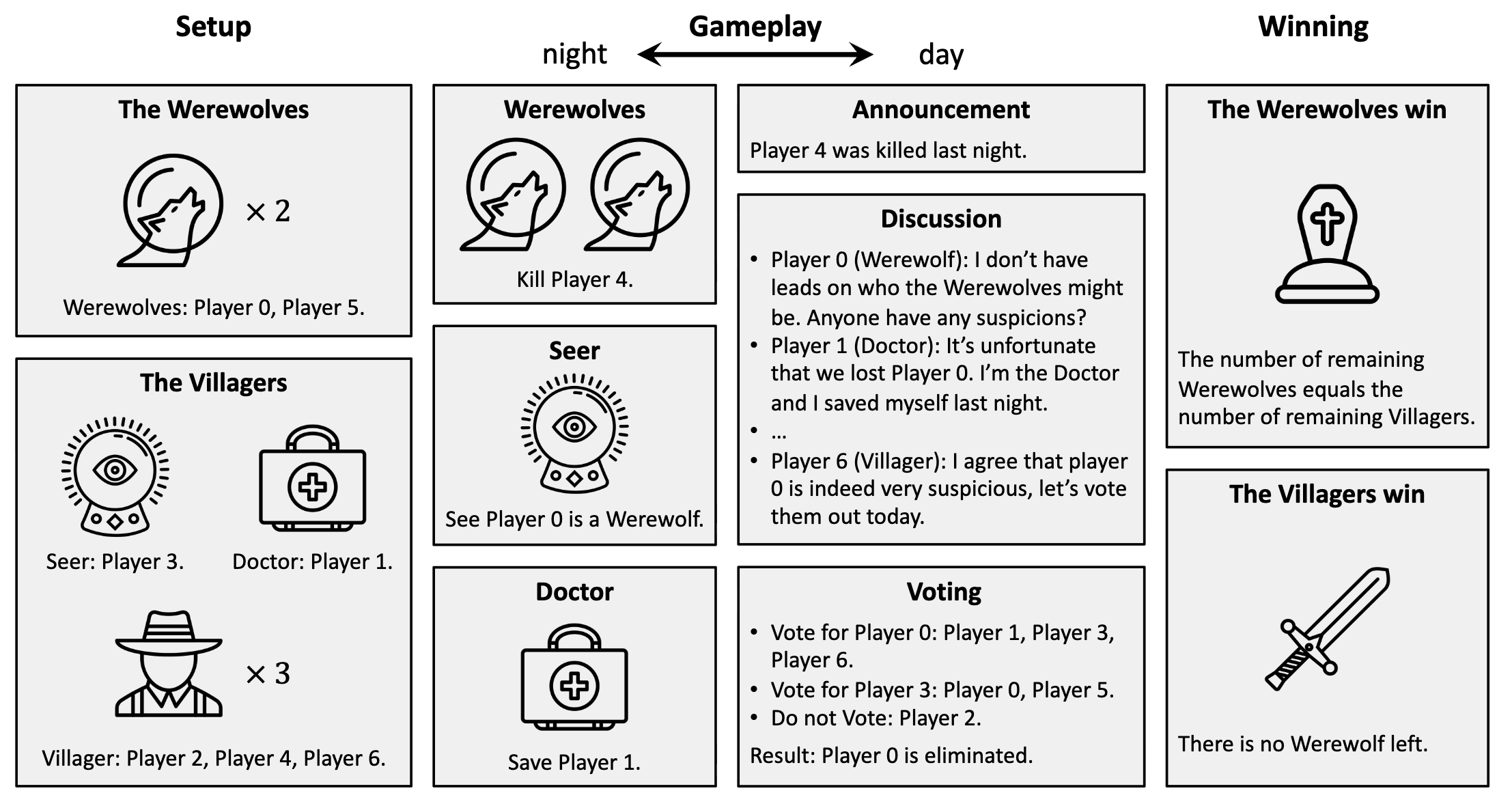
News
2026 年 4 月 14 日,智元机器人在龙旗科技南昌平板制造工厂开启长达 8 小时的真实产线作业直播,2283次任务零失误,成功率100%,面向全球公开验证全球首个具身智能 3C 精密制造产线规模化落地成果。智元精灵 G2 以产线 “正式员工” 身份,在高速流水线上完成精密上下料、人机协同全流程作业。标志具身智能正式迈入工业级常态化部署阶段,成为全球具身智能产业商用落地的里程碑事件。
4月13日,清华大学-自变量机器人科技(深圳)有限公司“下一代具身基座模型”产学研深度融合专项启动会暨指导委员会第一次会议在清华大学电子工程馆7层顺利召开。清华大学电子工程系主任沈渊、专项指导委员会主任汪玉、专项指导委员会秘书长于超,以及自变量机器人科技(深圳)有限公司创始人&首席执行官,专项指导委员会主任王潜、联合创始人&首席技术官王昊等共同出席本次会议。
Talks
Sponsors




